2020. 4. 12. 19:54
저는 요즘 소액으로 주식 투자를 해보고 있는 중인데
소소하게 투자를 해서 소소하게 잃고있는 중입니다.
그런데 저번주에는 갑자기 어떤 회사 주식에 꽂혀서 그 주식을 몰빵해서 샀고
가격이 내려도 추가 구입해서 평단가를 맞추는 등의 노력을 했지만
금요일날 결국 그 회사 주식이 폭락하여 3000 초반대까지 떨어져 원금의 10퍼센트를 잃고 손절하고 말았습니다.
그러다가 오늘은 꿈에서 손절한 주식이 8000원까지 올라가는 악몽을 꾸고 말았습니다.
결국 내가 뭐가 부족해서 계속 잃는것인지 생각해보았는데
생각해보면 제가 샀던 주식이 올랐던 적도 꽤나 있었습니다. 그런데도 손해만 보고 있었고요
저에게 부족한건 적절한때 손절 익절을 하는 능력(?)이 부족했던것이 아닐까 싶습니다.
그래서 생각해봤는데 손절 익절을 mts에 모두 맡기면 오히려 잃는 돈이 줄어들지 않을까 싶었고
주식을 구입한 후 +-3%가 되면 자동으로 판매를 하도록 설정을 해놓으면 어떨까 하고 생각을 했습니다.
보기에는 그럴듯 하지만 진짜로 저렇게 한다고 이익을 볼 수 있을까요?
물론 실제로 저런식으로 거래를 해서 이익을 보는 사람도 많이 있겠지만
결국 저런 방식으로 거래를 하는것도 오를 주식을 사야 얻는거고 또 오를 타이밍에 사야 이익을 볼텐데요
오를 주식을 미리 알 수는 없지만 어떤 상황에서 사야 오를지에 대해서 알 수 있을까 싶어서
과거의 자료를 보고 간단하게 차트를 만드는 코드를 만들어보았습니다.
이 코드를 만들기 위해서 우선 주식 프로그램에서
저번주 금요일 거래량이 많았던 종목들의 하루치의 데이터를 다운받았습니다.
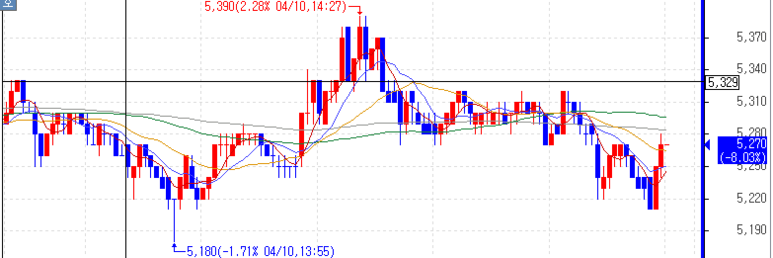
그리고 데이터를 엑셀 파일로 다운받았습니다.
그리고 파이썬에서 다운받은 엑셀 파일을 읽어들여 제가 원하는 결과를 출력하도록 코드를 작성하겠습니다.
규칙은 간단한데
어떤 시점에서 주식을 구입했을 경우 해당 주식이 +3% 가 되는것이 먼저인지 -3%가 되는것이 먼저인지를
출력하는것 입니다.
데이터는 분단위의 봉차트 데이터로 시가 고가 저가 종가에 다른 데이터도 더 있지만
시가 고가 저가 데이터만을 사용하도록 하겠습니다.
만약 09:00에 시가로 주식을 개당 1000원에 구입했을 경우
09:05분에 고가가 1030이 되고 09:06분에 저가가 970원이 된다면
09:05분에 1030원에 에 익절하는 형식입니다.
아래는 작성한 코드입니다.
import pandas as pd
import os
import matplotlib.pyplot as plt
from matplotlib import pyplot
import datetime
from matplotlib import dates
path = "./excel/"
file_list = os.listdir(path)
print ("file_list: {}".format(file_list))
plt.rcParams["figure.figsize"] = (14,7)
plt.rcParams['lines.linewidth'] = 2
plt.rcParams['lines.color'] = 'r'
plt.rcParams['axes.grid'] = False
p = 0.03
for file in file_list:
if file.find('xlsx') < 0 and file.find('xls') < 0:
continue
print(file)
xlsx = pd.read_excel(path + file)
color = []
for i in range(len(xlsx['시가'])):
color.append(0)
for i in reversed(range(0, xlsx.shape[0])):
for j in reversed(range(0, i-1)):
if xlsx['시가'][i] + xlsx['시가'][i] * p < xlsx['고가'][j]:
color[i] = 1
# print(xlsx['시간'][i], ",", xlsx['시가'][i], ",", p, ",", "익절" , xlsx['고가'][j] , xlsx['시간'][j], color[i])
break
if xlsx['시가'][i] - xlsx['시가'][i] * p > xlsx['저가'][j]:
color[i] = 2
# print(xlsx['시간'][i], ",", xlsx['시가'][i], ",", p, ",", "손절" , xlsx['저가'][j] , xlsx['시간'][j], color[i])
break
fig, ax = plt.subplots()
converted_dates = list(map(datetime.datetime.strptime, xlsx['시간'], len(xlsx['시간'])*['%m/%d,%H:%M']))
x_axis = converted_dates
formatter = dates.DateFormatter('%H:%M')
ax.xaxis.set_major_formatter(formatter)
ax.plot([],[])
ax.scatter(x_axis, xlsx['시가'], c = color)
plt.show()
결과를 차트로 출력하는데
위의 규칙을 그대로 사용하여
청록색일때 구입하면 익절
노란색일때 구입하면 손절
보라색일때 구입하면 손절도 익절도 하지 않습니다.
결과를 보면 저번 금요일 시점의 이 주식은 정말 특별한 타이밍이 아니면 이익을 보기 힘들었을거라는 결과입니다.
다른 회사들의 결과를 보겠습니다.

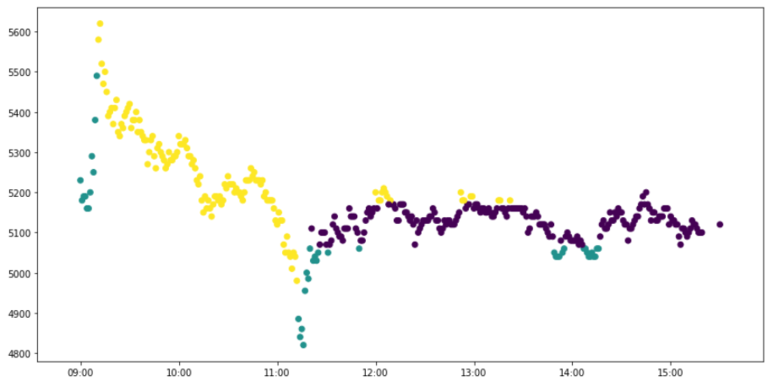

돈벌기 참 힘드네요
결과만 보면 주식 가격이 급격하게 내려갔을 때 구입하면 가격이 다시 회복되면서 익절을 하게되는 경우가 많은데
가장 첫번째 그래프처럼 다시 안올라가고 쭉 내려가기만 하는 경우도 있어서 그경우는 무조건 손해만 입겠네요.
결국 타이밍도 중요하지만 좋은 종목을 골라서 거래하는게 더 중요한것 같습니다.
'IT > 개발' 카테고리의 다른 글
| Simple Gallary Server (0) | 2021.01.10 |
|---|---|
| Airsonic 로컬가사를 출력하도록 소스코드 수정하기 (0) | 2020.12.24 |
| 음악 서버 프로그램 + 안드로이드 클라이언트 비교 그리고 Airsonic (0) | 2020.12.24 |
| 각종 테스트를 위한 더미 서버 프로그램 (0) | 2020.12.24 |
| 케라스 이미지 분류 연습 (0) | 2020.12.24 |