2020. 4. 3. 14:14
인터넷에 있는 케라스 이미지 분류 코드를 이용해 이미지 분류 연습을 해 보았습니다.
연습을 위해 이미지셋을 다운받아서 테스트 해보았더니 그럭저럭 90퍼센트 이상의 정확도가 나오는것을 확인할 수 있었습니다.
하지만 이미 있는 이미지로만 해보면 재미가 없으니 새로운 이미지 셋을 만들어 연습해 보았습니다.
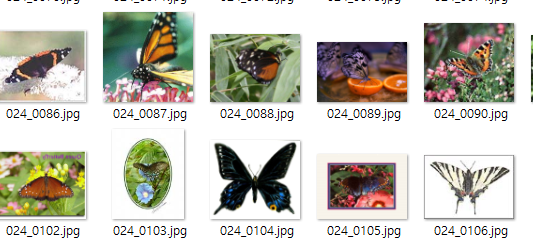 깔끔하게 잘 정리된 이미지셋들
깔끔하게 잘 정리된 이미지셋들
우선 이미지셋을 만들기 위해 제가만든 이미지 다운로더 프로그램을 사용하여 이미지를 다운로드 하였습니다.

이번에 테스트 해볼 이미지셋은 아이돌 마스터의
시마무라 우즈키,
혼다 미오,
시부야 린
이렇게 세명의 캐릭터 이미지로 분류되는 이미지셋입니다.

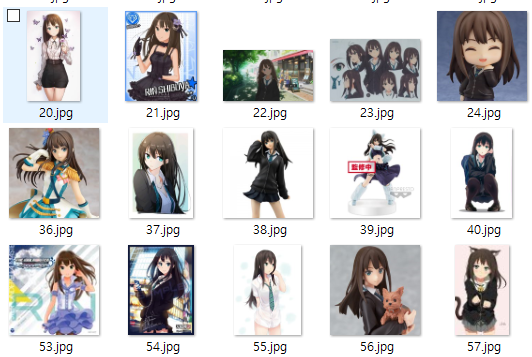
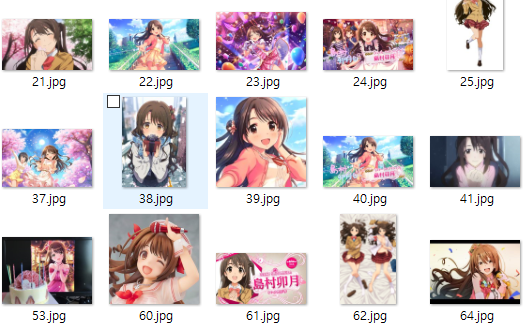
각각 캐릭터 이미지를 약 100개씩 준비하였습니다.
그런데 이미지들이 통일성이 없고 배경색이나 색들도 완전히 각양각색입니다.
이미지마다의 공통점이라고는 해당 캐릭터들의 얼굴이 들어가 있다는점 밖에는 없네요
이런 이미지로 이미지 분류가 가능할지 잘 모르겠습니다.
각각의 이미지를 uzuki, rin, mio 폴더에 집어넣고 이미지셋을 데이터로 만들었습니다.
from sklearn.model_selection import cross_validate
from sklearn.model_selection import train_test_split
import cv2
from PIL import Image
import os, glob
import numpy as np
caltech_dir = "./lib/img"
categories = ["mio","rin","uzuki"]
nb_classes = len(categories)
image_w = 64
image_h = 64
pixels = image_w * image_h * 3
X = []
Y = []
for idx, cat in enumerate(categories):
print(cat)
label = [0 for i in range(nb_classes)]
label[idx] = 1
image_dir = caltech_dir + "/" + cat
print(image_dir)
files = glob.glob(image_dir+"/*.jpg")
for i, f in enumerate(files):
print(f)
img = cv2.imread(f)
img = cv2.resize(img, None, fx=64/img.shape[1], fy=64/img.shape[0])
X.append(img/256)
Y.append(label)
X = np.array(X)
Y = np.array(Y)
X = np.array(X)
Y = np.array(Y)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y)
xy = (X_train, X_test, Y_train, Y_test)
np.save("./lib/obj.npy", xy)
그 후 이미지 데이터를 이용하여 학습을 진행하였습니다.
from keras.models import Sequential
from keras.layers import MaxPooling2D
from keras.layers import Conv2D
from keras.layers import Dropout, Activation, Dense, Flatten
import h5py
import numpy as np
import cv2
import os
categories = ["mio","rin","uzuki"]
nb_classes = len(categories)
X_train, X_test, Y_train, Y_test = np.load('./lib/obj3.npy', allow_pickle=True)
print('Xtrina_shape', X_train.shape)
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape[1:], padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy', optimizer='Adam', metrics=['accuracy'])
hdf5_file = "./lib/obj-model.hdf5"
if os.path.exists(hdf5_file):
model.load_weights(hdf5_file)
else:
model.fit(X_train, Y_train, batch_size=32, epochs=50)
model.save_weights(hdf5_file)
score = model.evaluate(X_test, Y_test)
print('loss=', score[0]) # loss
print('accuracy=', score[1]) # acc
마지막으로 트레이닝 된 데이터를 이용하여 테스트셋의 정확도를 확인해 보겠습니다.
중복되지 않는 이미지를 따로 모아 테스트 하였습니다.
from keras.models import Sequential
from keras.layers import MaxPooling2D
from keras.layers import Conv2D
from keras.layers import Dropout, Activation, Dense, Flatten
import h5py
import numpy as np
import cv2
import os
categories = ["mio","rin","uzuki"]
nb_classes = len(categories)
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape[1:], padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy', optimizer='Adam', metrics=['accuracy'])
hdf5_file = "./lib/obj-model.hdf5"
model.load_weights(hdf5_file)
import glob
X = []
Y = []
files = glob.glob("./lib/img/test/*.jpg")
for i, f in enumerate(files):
print(f)
img = cv2.imread(f)
img = cv2.resize(img, None, fx=64/img.shape[1], fy=64/img.shape[0])
X.append(img/256)
X = np.array(X)
Y = np.array(Y)
Y = model.predict(X)
c1 = 0;
c2 = 0;
for i in range(len(Y)):
for j in range(len(Y[i])):
if Y[i][j] == np.max(Y[i]):
c1 = c1 + 1
tmp1 = files[i].split('\\')[1].split(' ')[0]
if(tmp1 == categories[j]):
c2 = c2 + 1
break
print(c1)
print(c2)
출력된 결과는
97 62
97개 테스트 중에 62개가 정답입니다. 약 63퍼센트의 정확도네요
절반도 안될줄 알았는데 생각보다 높게 나왔습니다.
물론 실제로 사용하기에는 정확도가 너무 낮지만
랜덤으로 찍어서 맞출 확률보다 약 2배나 높은 확률입니다.
다만 테스트 자체의 신뢰성이 조금 의심됩니다...
이미지셋 자체가 너무 적은게 문제인것 같습니다.
정리되지 않은 이미지들로 이정도라면 정리된 데이터로 테스트 해보면 훨씬 높은 정확도가 나올것 같습니다.
예를들면 캐릭터 얼굴만 잘라내서 트레이닝 시키고 테스트하면 90퍼센트 이상의 정확도를 구할 수 있지 않을까요?
그건 나중에 따로 해보도록 하겠습니다.
참고
https://hoony-gunputer.tistory.com/entry/keras%EC%83%89-%EC%9E%88%EB%8A%94-%EC%9D%B4%EB%AF%B8%EC%A7%80-%EB%B6%84%EB%A5%98%ED%95%98%EA%B8%B02